Chaos Engineering Through Staged Resiliency - Stage 1
In spite of what the name may suggest, Chaos Engineering is a disciplined approach of identifying potential failures before they become outages. Ultimately, the goal of Chaos Engineering is to create more stable and resilient systems. There is some disagreement in the community about proper terminology, but regardless of which side of the Chaos Engineering vs Resilience Engineering debate you come down on, most engineers probably agree that proper implementation is more important than naming semantics.
Creating resilient software is a fundamental necessity within modern cloud applications and architectures. As systems become more distributed the potential for unplanned outages and unexpected failure significantly increases. Thankfully, Chaos and Resilience Engineering techniques are quickly gaining traction within the community. Many organizations – both big and small – have embraced Chaos Engineering over the last few years. In his fascinating ChaosConf 2018 talk titled Practicing Chaos Engineering at Walmart, Walmart’s Director of Engineering Vilas Veeraraghavan outlines how he and the hundreds of engineering teams at Walmart have implemented Resilience Engineering. By creating a robust series of “levels” or “stages” that each engineering team can work through, Walmart is able to progressively improve system resiliency while dramatically reducing support costs.
This blog series expands on Vilas’ and Walmart’s techniques by diving deep into the five Stages of Resiliency. Each post examines the necessary components of a stage, describes how those components are evaluated and assembled, and outlines the step-by-step process necessary to move from one stage to the next.
This series also digs into the specific implementation of each stage by progressing through the entire process with a real-world, fully-functional API application hosted on AWS. We’ll go through everything from defining and executing disaster recovery playbook scenarios to improving system architecture and reducing RTO, RPO, and applicable support costs for this example app.
With a bit of adjustment for your own organizational needs, you and your team can implement similar practices to quickly add Chaos Engineering to your own systems with relative ease. After climbing through all five stages your system and its deployment will be almost entirely automated and will feature significant resiliency testing and robust disaster recovery failover.
NOTE: The remainder of this article will use the term team to indicate a singular group that is responsible for an application that is progressing through the resiliency stages.
Prerequisites
Before you can begin moving through the resiliency stages there are a few prerequisite steps you’ll need to complete. Most of these requirements are standard fare for a well-designed system, but ensuring each and every unique application team is fully prepared for the unknown is paramount to developing resilient systems.
1. Establish High Observability
Microservice and clustered architectures favor the scalability and cost-efficiency of distributed computing, but also require a deep understanding of system behavior across a large pool of services and machines. Robust observability is a necessity for most modern software, which tends to be comprised of these complex distributed systems.
- Monitoring: The act of collecting, processing, aggregating, and displaying quantitative data about a system. These data may be anything from query counts/types and error counts/types to processing times and server lifetimes. Monitoring is a smaller subset of the overall measure of observability.
- Observability: A measure of the ability to accurately infer what is happening internally within a system based solely on external information.
Continuous monitoring is critical to catch unexpected behavior that is difficult to reproduce, but at least historically, monitoring has largely focused on measuring “known unknowns.” By contrast, a highly-distributed system often requires tracking down, understanding, and preparing for a multitude of “unknown unknowns” – obscure issues that have never happened before, and may never happen again. A properly observable system is one that allows your team to answer new questions about the internals of the system without the need to deploy a new build. This kind of observability is often referred to as “black box monitoring,” as it allows your team to draw conclusions about unknowable events without using the internals of the system.
Most importantly, high observability is critically important when implementing Chaos Engineering techniques. As Charity Majors, CEO of Honeycomb, puts it, “Without observability, you don’t have ‘chaos engineering’. You just have chaos.”
2. Define the Critical Dependencies
Start by documenting every application dependency that is required for the application to function at all. This type of dependency is referred to as a critical dependency.
3. Define the Non-Critical Dependencies
Once all critical dependencies are identified then all remaining dependencies should be non-critical dependencies. If the core application can still function – even in a degraded state – when a dependency is missing, then that dependency is considered non-critical.
4. Create a Disaster Recovery Failover Playbook
Your team should create a disaster recovery plan specific to failover. A disaster recovery failover playbook should include the following information, at a minimum:
- Contact information: Explicitly document all relevant contact info for all team members. Identifying priority team members based on seniority, role, expertise, and the like will prove beneficial for later steps.
- Notification procedures: This should answer all the “Who/What/When/Why/How” questions for notifying relevant team members.
- Failover procedures: Deliberate, step-by-step instructions for handling each potential failover scenario.
TIP: Not sure which failover scenarios to expect or plan for? Unable to determine if a dependency is critical vs non-critical? Consider running a GameDay to better prepare for and test specific scenarios in a controlled manner. Check out How to Run a GameDay for more info.
5. Create a Critical Dependency Failover Playbook
A critical dependency failover playbook is a subset of the disaster recovery failover playbook and it should detail the step-by-step procedures for handling the potential failover scenarios for each critical dependency.
6. Create a Non-Critical Dependency Failover Playbook
The final prerequisite is to determine how non-critical dependency failures will impact the system. Your team may not necessarily have failover procedures in place for non-critical dependencies, so this process can be as simple as testing and documenting what happens when each non-critical dependency is unavailable. Be sure to gauge the severity of the failure impact on the core application, which will provide the team with a better understanding of the system and its interactions (see Recovery Objectives).
Recovery Objectives
Most disaster recovery playbooks define the goals and allotted impact of a given failure using two common terms: Recovery Time Objective and Recovery Point Objective.
- Recovery Time Objective (RTO): The maximum period of time in which the functionality of a failed service should be restored. For example, if a service with an RTO of twelve hours experiences an outage at 5:00 PM then functionality should be restored to the service by 5:00 AM the next morning.
- Recovery Point Objective (RPO): The maximum period of time during which data can be lost during a service failure. For example, if a service with an RPO of two hours experiences an outage at 5:00 PM then only data generated between 3:00 PM and 5:00 PM should be lost – all existing data prior to 3:00 PM should still be intact.
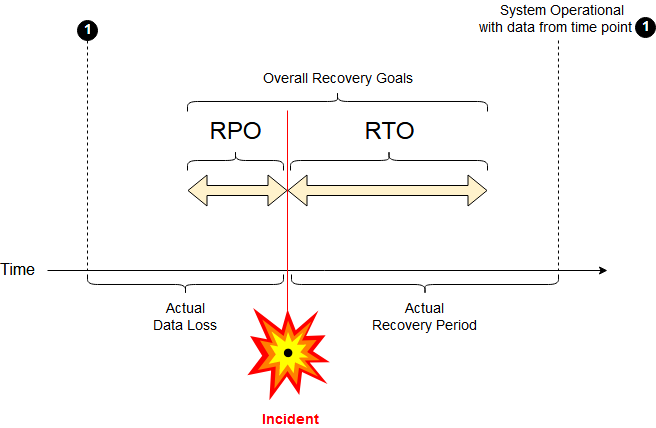 RTO & RPO Diagrammed – Source: Wikipedia
RTO & RPO Diagrammed – Source: Wikipedia
Complete and Publish Prerequisites
Ensure that all Prerequisites have been met. All playbooks, dependency definitions, and other relevant documentation should be placed in a singular, globally accessible location so every single team member has immediate access to that information. Maintaining a single repository for the information also maintains consistency across the team, so there’s never any confusion about the steps in a particular scenario or what is defined as a critical dependency.
Team-Wide Agreement on Playbooks
With unfettered access to all documentation, the next step is to ensure the entire team agrees with all documented information as its laid out. If there is disagreement about the best way to approach a given failover scenario, or about the risk and potential impact of a non-critical dependency failure, this is the best time to suss out those differences of opinion and come to a unanimous “best” solution. A healthy, active debate provides the team with a deeper understanding of the system and encourages the best ideas and techniques to bubble up to the surface.
While the goal is agreement on the playbooks currently laid out, documentation can (and should) be updated in the future as experiments shed new light on the system. The team should be encouraged and empowered to challenge the norms in order to create a system that is always adapting and evolving to be as resilient as possible.
Manually Execute a Failover Exercise
The last step is to manually perform a failover exercise. The goal of this exercise is to verify that the disaster recovery failover playbook works as expected. Therefore, the step-by-step process defined in the playbook should be followed exactly as documented.
WARNING: If an action or step is not explicitly documented within a playbook then it should be ignored. If the exercise fails or cannot be completed this likely indicates that the playbook needs to be updated.
Resiliency Stage 1: Implementation Example
Throughout this series, we’ll take a simple yet real-world application through the entire staging process to illustrate how a team might progress their application through all five resiliency stages. While every application and system architecture is unique, this example illustrates the basics of implementing every step within a stage, to provide you with a jumping off point for staged resiliency within your own system.
The Bookstore example application is a publicly accessible API for a virtual bookstore. The API includes two primary endpoints: /authors/ and /books/, which can be used to add, update, or remove Authors and Books, respectively.
Bookstore’s architecture consists of three core components, all of which are housed within Amazon Web Services.
- API: The API is created with Django and the Django REST Framework and is hosted on an Amazon EC2 instance running NGINX.
- Database: A PostgreSQL database handles all data and uses Amazon RDS.
- CDN: All static content is collected in and served from an Amazon S3 bucket.
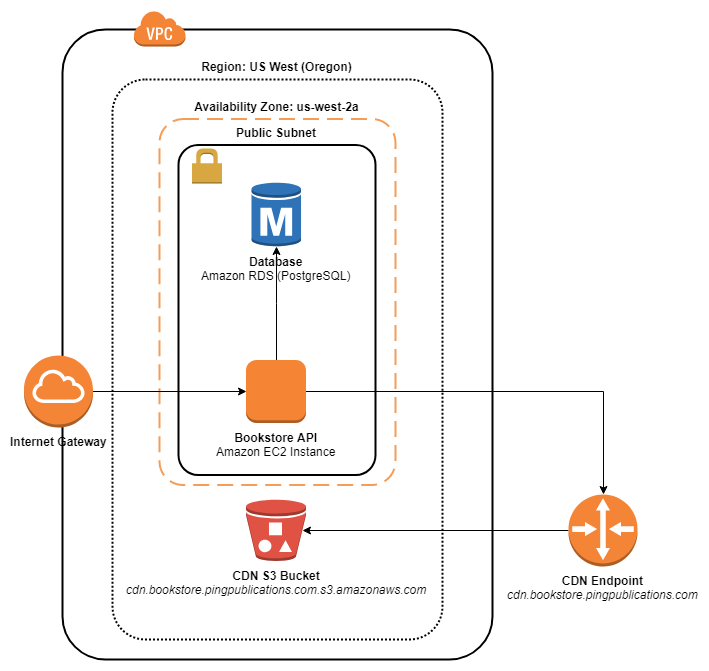 Initial System Architecture
Initial System Architecture
The web API is at the publicly accessible http://bookstore.pingpublications.com endpoint. The web API, database, and CDN endpoints are DNS-routed via Amazon Route53 to the underlying Amazon EC2, RDS, and Amazon S3 buckets, respectively.
Here’s a simple request to the /books/ API endpoint.
$ curl http://bookstore.pingpublications.com/books/ | jq
[
{
"url": "http://bookstore.pingpublications.com/books/1/",
"authors": [
{
"url": "http://bookstore.pingpublications.com/authors/1/",
"birth_date": "1947-09-21",
"first_name": "Stephen",
"last_name": "King"
}
],
"publication_date": "1978-09-01",
"title": "The Stand"
}
]
WARNING: The initial design and architecture for the Bookstore sample application is intentionally less resilient than a full production-ready system. This leaves room for improvement as progress is made through the resiliency stages throughout this series.
Prerequisites
We begin the example implementation by defining all prerequisites for the Bookstore app.
0. Define System Architecture
It may be useful to take a moment to define the basic components of the system, which can then be referenced throughout your playbooks. Below are the initial services for the Bookstore app.
| Service | Platform | Technologies | AZ | VPC | Subnet | Endpoint |
|---|---|---|---|---|---|---|
| API | Amazon EC2 | Django, Nginx | us-west-2a | bookstore-vpc | bookstore-subnet-2a | bookstore.pingpublications.com |
| Database | Amazon RDS | PostgreSQL 10.4 | us-west-2a | bookstore-vpc | bookstore-subnet-2a | db.bookstore.pingpublications.com |
| CDN | Amazon S3 | Amazon S3 | N/A | N/A | N/A | cdn.bookstore.pingpublications.com |
1. Define the Critical Dependencies
At this early stage of the application, all dependencies are critical.
| Dependency | Criticality Period | Manual Workaround | RTO | RPO | Child Dependencies |
|---|---|---|---|---|---|
| API | Always | Manual Amazon EC2 Instance Restart | 12 | 24 | Database, CDN |
| Database | Always | Manual Amazon RDS Instance Restart | 12 | 24 | N/A |
| CDN | Always | Manual Amazon S3 Bucket Verification | 24 | 24 | N/A |
A criticality period is useful for dependencies that are only considered “critical” during a specific period of time. For example, a database backup service that runs at 2:00 AM PST every night may have a criticality period of 2:00 AM - 3:00 AM PST. This is also a good time to evaluate initial acceptable RTO and RPO values. These values will decrease over time as resiliency improves, but setting a baseline goal provides a target to work toward.
2. Define the Non-Critical Dependencies
The Bookstore app is so simple that it doesn’t have any non-critical dependencies – if a service fails, the entire application fails with it.
3. Create a Disaster Recovery Failover Playbook
The first part of a disaster recovery failover playbook should contain contact information for all relevant team members, including the services those members are related to and their availability.
| Team Member | Position | Relevant Services | Phone | Availability | |
|---|---|---|---|---|---|
| Alice | Director of Technology | ALL | alice@example.com | 555-555-5550 | 9 - 5, M - F |
| Bob | Lead Developer, Bookstore API | Bookstore API | bob@example.com | 555-555-5551 | 9 - 5, M - F; 10 - 2, S & S |
| Christina | Site Reliability Engineer | ALL | christina@example.com | 555-555-5552 | On-call |
To define the proper notification procedures it may help to add an organizational chart to the playbook.
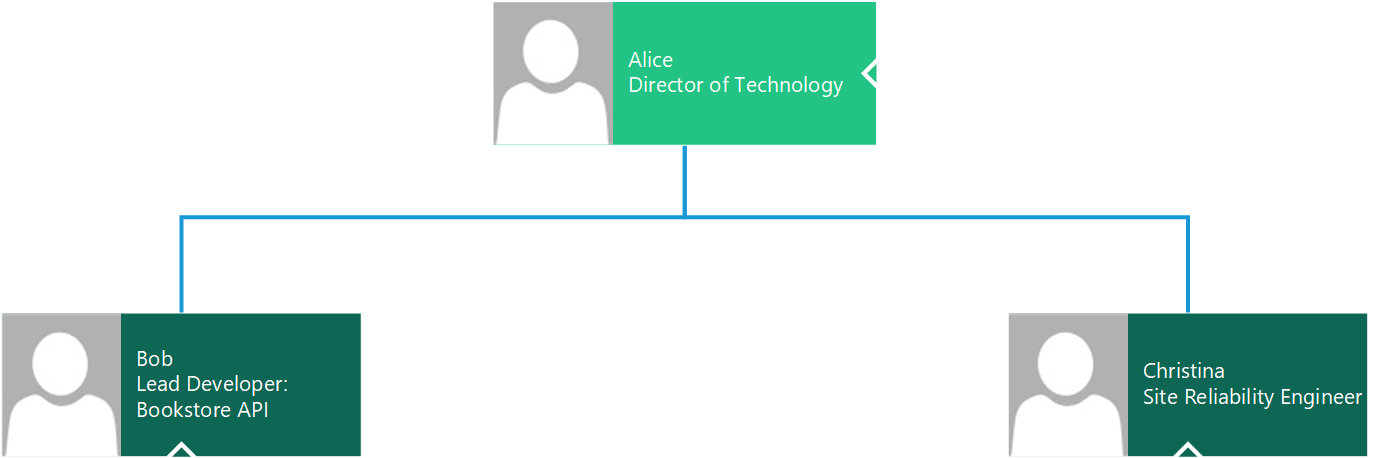 Organizational Chart
Organizational Chart
This can be used in conjunction with the contact information table to determine which team members should be contacted – and in what priority – when a given service fails.
The final part of the disaster recovery failover playbook is to explicitly document the step-by-step procedures for every failover scenario. For the Bookstore application, we’ll just provide a single failover scenario plan for when the database fails, but this can be expanded as necessary for all other failover scenarios.
Scenario: Bookstore API Failure
The current architecture of the Bookstore app is limited to a manual Backup & Restore disaster recovery strategy.
Disaster Recovery Leads
- Primary: Bob, Lead Developer, Bookstore API
- Secondary: Alice, Director of Technology
Severity
- Critical
PURPOSE: The severity level of this particular failover. Severity should be a general indicator of acceptable RTO/RPO metrics, as well as how critically dependent the service is.
Recovery Procedure Overview
- Manually verify if the API server has failed, or if the server is available but the Django API app failed.
- If server failure: Manually restart API server.
- If Django API app failure: Manually restart Django API app.
- If neither restart solution works, propagate replacement server using prepared backup Amazon Machine Image (AMI).
- Verify backup instance is functional.
- Update DNS routing.
Basic Assumptions
- Amazon S3, Amazon RDS, Amazon Route 53, and Amazon EC2 are all online and functional.
- Frequent AMI backups are generated for the application instance.
- Application code can be restored from code repository with minimal manual effort.
PURPOSE: Indicates the basic assumptions that can be made during the recovery process. Assumptions are typically factors outside of your control, such as third-party vendor availability.
Recovery Time Objective
- 12 Hours
Recovery Point Objective
- 24 Hours
Recovery Platform
- Amazon EC2
t2.microinstance onus-west-2aAvailability Zone with NGINX, Python, and Django Bookstore application configured and installed from the latest release.
PURPOSE: Indicate the specific technologies, platforms, and services that are necessary to complete the recovery procedure.
Recovery Procedure
-
Manually verify the
bookstore-apiinstance availability on Amazon EC2.$ curl http://bookstore.pingpublications.com curl: (7) Failed to connect to bookstore.pingpublications.com port 80: Connection refused-
If the
bookstore-apiinstance is active but Bookstore Django application is failing then manually restart app from the terminal.sudo systemctl restart gunicorn -
If Bookstore Django application remains offline then manually restart the instance and recheck application availability.
-
-
If the
bookstore-apiEC2 instance has completely failed and must be replaced then propagate a new Amazon EC2 instance from thebookstore-api-ec2-imageAMI backup.Use the pre-defined
bookstore-api-ec2launch template.$ aws ec2 run-instances --launch-template LaunchTemplateName=bookstore-api-ec2 532151327118 r-0e57eca4a2e78d479 ...Default values can be overridden as seen below.
aws ec2 run-instances \ --image-id ami-087ff330c90e99ac5 \ --count 1 \ --instance-type t2.micro \ --key-name gabe-ping-pub \ --security-group-ids sg-25268a50 sg-0f818c22884a88694 \ --subnet-id subnet-47ebaf0c -
Confirm the instance has been launched and retrieve the public DNS and IPv4 address.
$ aws ec2 describe-instances --filters "Name=image-id,Values=ami-087ff330c90e99ac5,Name=instance-state-code,Values=16" --query "Reservations[*].Instances[*].[LaunchTime,PublicDnsName,PublicIpAddress]" 2018-11-09T04:37:32.000Z ec2-54-188-3-235.us-west-2.compute.amazonaws.com 54.188.3.235NOTE: The
filtersused in the command above searched for Running instances based on the AMIimage-id. If multiple instances match these filters then theLaunchTimevalue retrieved from the query will help determine which instance is the latest launched. -
SSH into the new
bookstore-apiinstance.ssh ec2-54-188-3-235.us-west-2.compute.amazonaws.com -
Pull latest Bookstore application code from the repository.
$ cd ~/apps/bookstore_api && git pull Already up to date. -
Restart application via
gunicorn.sudo systemctl restart gunicorn -
On a local machine verify backup instance is functional, the public IPv4 address is available, and the Bookstore app is online.
$ curl ec2-54-188-3-235.us-west-2.compute.amazonaws.com | jq { "authors": "http://ec2-54-188-3-235.us-west-2.compute.amazonaws.com/authors/", "books": "http://ec2-54-188-3-235.us-west-2.compute.amazonaws.com/books/" } - Update the Amazon Route 53 DNS
Arecord to point to the newbookstore-apiEC2 instance IPv4 address. -
Once DNS propagation completes then verify that the API endpoint is functional.
$ curl bookstore.pingpublications.com | jq { "authors": "http://bookstore.pingpublications.com/authors/", "books": "http://bookstore.pingpublications.com/books/" }
Test Procedure
- Manually verify that
bookstore.pingpublications.comis accessible and functional. - Confirm that critical dependencies are functional and also connected (database and CDN).
PURPOSE: Indicates the test procedures necessary to ensure the system is functioning normally.
Resume Procedure
- Service is now fully restored.
PURPOSE: For more complex systems this final procedure should provide steps for resuming normal service.
4. Create a Critical Dependency Failover Playbook
Scenario: Database Failure
Disaster Recovery Leads
- Primary: Alice, Director of Technology
- Secondary: Bob, Lead Developer, Bookstore API
Severity
- Critical
Recovery Procedure Overview
- Manually verify database availability through Amazon RDS monitoring.
- If unavailable, restart.
- If still unavailable, manually propagate replica.
- If necessary, restore from the most recent snapshot.
Basic Assumptions
- Amazon RDS is online and functional.
- Database backups are available.
- AWS Support contact is available for additional assistance.
Recovery Time Objective
- 12 Hours
Recovery Point Objective
- 24 Hours
Recovery Platform
- PostgreSQL 10.4 database with identical configuration running on Amazon RDS with minimal
us-west-2aAvailability Zone.
Recovery Procedure
- Disaster recovery team member should manually verify database availability through Amazon RDS monitoring.
- Manually restart the
bookstore-dbinstance.- If
bookstore-dbis back online, proceed to Resume Procedure.
- If
- If
bookstore-dbremains unavailable manual propagate a replica Amazon RDS PostgreSQL 10.4 instance. - If replacement created, update DNS routing on Amazon Route 53 for
db.bookstore.pingpublications.comendpoint. - (Optional): Restore data from the most recent snapshot within acceptable RPO.
Test Procedure
- Manually confirm a connection to public
bookstore-dbendpoint (db.bookstore.pingpublications.com). - Confirm that
bookstore-apican access thebookstore-dbinstance.
Resume Procedure
- Service is now fully restored.
- If necessary, perform manual data recovery.
Scenario: CDN Failure
Disaster Recovery Leads
- Primary: Alice, Director of Technology
- Secondary: Christina, Site Reliability Engineer
Severity
- Critical
Recovery Procedure Overview
- Manual verification of applicable Amazon S3 bucket.
- If unavailable, manually recreate bucket and upload a backup snapshot of static data.
Basic Assumptions
- Amazon S3 is online and functional.
- Static asset backups are available.
- Static asset collection can be performed remotely from the EC2
bookstore-apiserver or locally via Djangomanage.py collectstaticcommand. - AWS Support contact is available for additional assistance.
Recovery Time Objective
- 24 Hours
Recovery Point Objective
- 24 Hours
Recovery Platform
- Amazon S3
privatebucket accessible by administrator AWS account.
Recovery Procedure
- Team member manually verifies Amazon S3
cdn.bookstore.pingpublications.combucket exists, is accessible, and contains all static content. - Manually recreate
cdn.bookstore.pingpublications.combucket. - Manually upload all static content to
cdn.bookstore.pingpublications.combucket. - If
cdn.bookstore.pingpublications.combucket exists but is non-functional, manually create the bucket, upload static content, and route the system to backup.
Test Procedure
- Confirm all static content exists in
cdn.bookstore.pingpublications.comAmazon S3 bucket. - Confirm public endpoint (
cdn.bookstore.pingpublications.com/static) is accessible for static content. - Confirm that
bookstore-apican accesscdn.bookstore.pingpublications.combucket and content.
Resume Procedure
- Service is now fully restored.
5. Create a Non-Critical Dependency Failover Playbook
The Bookstore example app doesn’t have any non-critical dependencies at the moment given its simple architecture (CDN > API Server < Database). However, progressing through each resiliency stage will require additional systems and services to maintain failure resilience, which will inherently add non-critical dependencies.
Complete and Available Prerequisites
- Status: Complete
All prerequisites for the Bookstore app have been met and all documentation has been dispersed among every member of the team.
Team-Wide Agreement on Playbooks
- Status: Complete
Every team member has agreed on the playbook/scenarios defined above.
Manually Execute a Failover Exercise
- Status: Complete
For this stage of the Bookstore app, we’ve manually performed the Scenario: Bookstore API Failure exercise.
Full manual restoration of the bookstore-api EC2 instance and the Bookstore app resulted in approximately 30 minutes of downtime. This is well under the initial RTO/RPO goals so we can reasonably update the playbooks. However, this manual process is still clunky and prone to errors, so there’s plenty of room for improvement.
Resiliency Stage 1 Completion
This post laid the groundwork for how to implement resilience engineering practices through thoughtfully-designed dependency identification and disaster recovery playbooks. We also broke down the requirements and steps of Resiliency Stage 1, which empowers your team to begin the journey toward a highly-resilient system. Stay tuned to the Gremlin Blog for additional posts that will break down the four remaining Stages of Resiliency!