Chaos Engineering Through Staged Resiliency - Stage 2
In Chaos Engineering Through Staged Resiliency - Stage 1 we explored how engineering teams at Walmart successfully identify and combat unexpected system failure using a series of “resiliency stages.” We also demonstrated the process of going through Stage 1 for the Bookstore API sample application. We showed that completing Resiliency Stage 1 requires the definition of a disaster recovery failover playbook, dependency failover playbooks, team-wide agreement on said playbooks, and the execution of a manual failover exercise.
In this second part, we’ll dive into the components of Resiliency Stage 2, which focuses on critical dependency failure testing in non-production environments.
Prerequisites
- Creation and agreement on Disaster Recovery and Dependency Failover Playbooks.
- Completion of Resiliency Stage 1.
Perform Critical Dependency Failure Tests in Non-Production
The most important aspect of Resiliency Stage 2 is testing the resilience of your systems when critical dependencies fail. However, this early in the process the system can’t be expected to handle such failures in a production environment, so these tests should be performed in a non-production setting.
Manual Testing Is Okay
Eventually, all experiments should be executed automatically, with little to no human intervention required. However, during Resiliency Stage 2 the team should feel comfortable performing manual tests. The goal here isn’t to test the automation of the system, but rather to determine the outcome and system-wide impact whenever a critical dependency fails.
Publish Test Results
After every critical dependency failure test is performed the results should be globally published to the entire team. This allows every team member to closely scrutinize the outcome of a given test. This encourages feedback and communication, which naturally provides an insightful evaluation from the members that are best equipped to analyze the test results.
Resiliency Stage 2: Implementation Example
At present the Bookstore sample app has no real concept of failover or resiliency – if the application or a critical dependency fails, the entire system fails along with it.
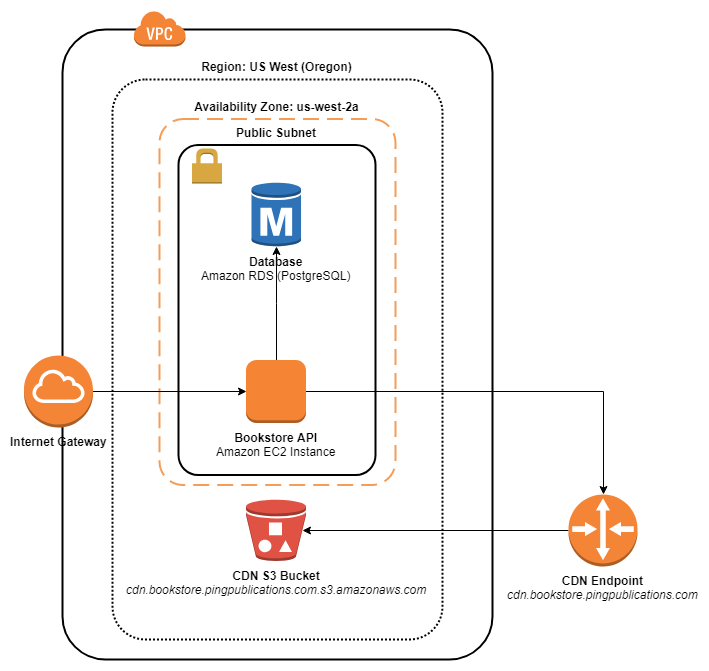 Bookstore App Architecture
Bookstore App Architecture
Completing Resiliency Stage 2 requires testing in a non-production environment, so this forces us to improve deployment and system resiliency by moving beyond a single point of failure. Since we’re taking advantage of AWS we could jump straight into implementing all the safety net features the AWS platform brings with it (e.g. auto-scaling, elastic load balancing, traffic manipulation, etc). However, going through each resiliency stage by meeting the minimal requirements provides more robust examples and lets us learn the intricacies of all components within the system.
Therefore, before we go through this stage we’ll be modifying the Bookstore architecture by adding a secondary staging environment. In fact, this is a good opportunity to use a blue/green deployment strategy. A blue/green configuration requires creating two parallel production environments.
As an example scenario, the blue environment is “active” and is handling production traffic. Meanwhile, the other environment (green) is used for staging application changes. Once the green environment has been fully tested then traffic is routed to the green environment. Green now becomes the live production environment while blue is unused and ready for the next staging phase. If something goes wrong during deployment to green, traffic can be quickly routed back to the still-active blue environment.
Adding a Staging App Environment
-
Create a new EC2 instance from the most recent launch template version. Optionally, we can specify tags such as
Nameto help differentiate between the two environments.aws ec2 run-instances --launch-template LaunchTemplateName=bookstore-api-ec2 \ --tag-specifications "ResourceType=instance,Tags=[{Key=Name,Value=bookstore-api-green}]" -
Verify the instance has been created by finding active instances generated from the same AMI.
$ aws ec2 describe-instances --filters "Name=image-id,Values=ami-087ff330c90e99ac5,Name=instance-state-code,Values=16" --query "Reservations[*].Instances[*].[LaunchTime,PublicDnsName,PublicIpAddress]" 2018-11-09T04:37:32.000Z ec2-54-188-3-235.us-west-2.compute.amazonaws.com 54.188.3.235 2018-11-09T07:44:38.000Z ec2-54-191-29-110.us-west-2.compute.amazonaws.com 54.191.29.110 -
SSH into new environment.
ssh ec2-54-191-29-110.us-west-2.compute.amazonaws.com -
Pull any new application changes and restart the application.
$ cd ~/apps/bookstore_api && git pull && sudo systemctl restart gunicorn From github.com:GabeStah/bookstore_api 0f1b811..ee6f15c master -> origin/master -
Verify that each instance environment is serving a different version of the application.
-
Here we check the app version for the current production endpoint.
$ curl bookstore.pingpublications.com/version | jq { "version": 3 } -
And for the
bookstore-api-greenenvironment.$ curl ec2-54-191-29-110.us-west-2.compute.amazonaws.com/version | jq { "version": 4 }
-
Configuring Multi-AZ RDS
The PostgreSQL database on Amazon RDS is not resilient – if the single instance fails, the entire application goes down. RDS provides a Multi-AZ Deployment solution, which automatically creates a synchronous database replica on another Availability Zone. In the event of a primary failure, the secondary performs an automatic failover so there is little to no downtime.
Modifying the existing bookstore-db RDS instance so it uses a Multi-AZ Deployment is fairly simple.
-
Confirm the instance is not using Multi-AZ.
$ aws rds describe-db-instances --db-instance-identifier bookstore-db --query "DBInstances[*].[AvailabilityZone,MultiAZ]" us-west-2a False -
Modify the instance by passing the
multi-azflag. In this case, we always want to apply changes immediately (rather than wait for the next scheduled maintenance window).aws rds modify-db-instance --db-instance-identifier bookstore-db --multi-az --apply-immediately -
It may take a few minutes for the modification to take effect. We can check the status within the
PendingModifiedValueskey structure to confirmMultiAZis waiting to be modified.$ aws rds describe-db-instances --db-instance-identifier bookstore-db --query "DBInstances[*].PendingModifiedValues.[MultiAZ]" True -
After about 10 minutes we can check the status once again to confirm that a Multi-AZ Deployment is now active.
$ aws rds describe-db-instances --db-instance-identifier bookstore-db --query "DBInstances[*].[AvailabilityZone,MultiAZ]" us-west-2a True
Amazon S3 Cross-Region Replication
The last critical dependency for the Bookstore app is the CDN, which relies on Amazon S3. While Amazon S3 is an extremely resilient system and not prone to downtime, there is still some precedent for Amazon S3 failure. Luckily, the service has the ability to automatically replicate objects between buckets within different AWS regions.
To accomplish this we’re working around a quirk with Amazon S3 bucket naming and DNS routing. Specifically, a CNAME DNS name must exactly match a referenced Amazon S3 bucket name. Therefore, we’ll continue using the cdn.bookstore.pingpublications.com.s3.amazonaws.com Amazon S3 bucket (and Route53 CNAME record), but this bucket is now the secondary CDN. A new Amazon S3 bucket named cdn-primary.bookstore.pingpublications.com is now the primary CDN bucket.
We then create a CloudFront endpoint that points to the cdn-primary bucket but uses the DNS CNAME cdn.bookstore.pingpublications.com. From there, Amazon Route53 failover properly handles requests based on whichever Amazon S3 bucket is available. This automates the CDN failover process.
-
Start by creating an Amazon CloudFront Distribution. The fields we need to set are as follows.
-
Origin Domain Name: This must be set the primary Amazon S3 bucket (
cdn-primary.bookstore.pingpublications.com.s3-us-west-2.amazonaws.com). -
Alternate Domain Names (CNAMEs): This should point to the root CDN endpoint (
cdn.bookstore.pingpublications.com).
-
Origin Domain Name: This must be set the primary Amazon S3 bucket (
-
Create an Amazon Route53 Health Check to check the health of the primary Amazon S3 bucket, which is behind the CloudFront endpoint created above.
$ aws route53 create-health-check --caller-reference BookstoreCloudfront --output json \ --health-check-config '{ "FullyQualifiedDomainName": "dqno94z16p2mg.cloudfront.net", "ResourcePath": "/static/status.json", "Type": "HTTP" }' \ --query "{Id: HealthCheck.Id}" { "Id": "352ef27f-213e-4dae-983e-62fd048ea7be" }TIP: We’ve added a
status.jsonfile to our static asset collection, which we’ll use to confirm the online status of both CDN buckets, as well as determine which bucket is currently serving our content. -
Create another Amazon Route53 Health Check to check the status of the secondary Amazon S3 bucket (
cdn.bookstore.pingpublications.com.s3.amazonaws.com).$ aws route53 create-health-check --caller-reference BookstoreS3 --output json \ --health-check-config '{ "FullyQualifiedDomainName": "cdn.bookstore.pingpublications.com.s3.amazonaws.com", "ResourcePath": "/static/status.json", "Type": "HTTP" }' \ --query "{Id: HealthCheck.Id}" { "Id": "e7fce91f-c82a-460f-b247-58c35790e39d" } -
Create a third Amazon Route53 Health Check that combines the two previous health checks. This combined health check is monitored by Amazon Route53 and automatically triggers failover from the primary to secondary CDN when the check fails. We need to pass the two health check
Idscreated above into this combined health check configuration.$ aws route53 create-health-check --caller-reference BookstoreCDN --output json --health-check-config '{ "HealthThreshold": 2, "Type": "CALCULATED", "ChildHealthChecks": [ "e7fce91f-c82a-460f-b247-58c35790e39d", "352ef27f-213e-4dae-983e-62fd048ea7be" ] }' { "HealthCheck": { "HealthCheckConfig": { "HealthThreshold": 2, "Type": "CALCULATED", "ChildHealthChecks": [ "352ef27f-213e-4dae-983e-62fd048ea7be", "e7fce91f-c82a-460f-b247-58c35790e39d" ], "Inverted": false }, "CallerReference": "BookstoreCDN", "HealthCheckVersion": 1, "Id": "99d5b3a0-7709-4553-934f-d0ac7bcd2eb3" }, } -
Finally, verify all CDN endpoints behave correctly and point to the proper Amazon S3 bucket.
-
Start by checking the primary Amazon S3 bucket.
$ curl http://cdn-primary.bookstore.pingpublications.com.s3-us-west-2.amazonaws.com/static/status.json { "online": true, "cdn": "primary" } -
The CloudFront endpoint routes to the primary bucket above.
$ curl http://dqno94z16p2mg.cloudfront.net/static/status.json { "online": true, "cdn": "primary" } -
The last part of the chain is the primary CDN endpoint, which routes to the CloudFront endpoint, and then onto the primary Amazon S3 bucket itself.
$ curl http://cdn.bookstore.pingpublications.com/static/status.json { "online": true, "cdn": "primary" } -
Finally, the secondary Amazon S3 bucket is properly retrieving the secondary static content.
$ curl http://cdn.bookstore.pingpublications.com.s3.amazonaws.com/static/status.json { "online": true, "cdn": "secondary" }
-
The app is now ready for failure testing. Here is the updated diagram showing the Bookstore app architecture for Resiliency Stage 2.
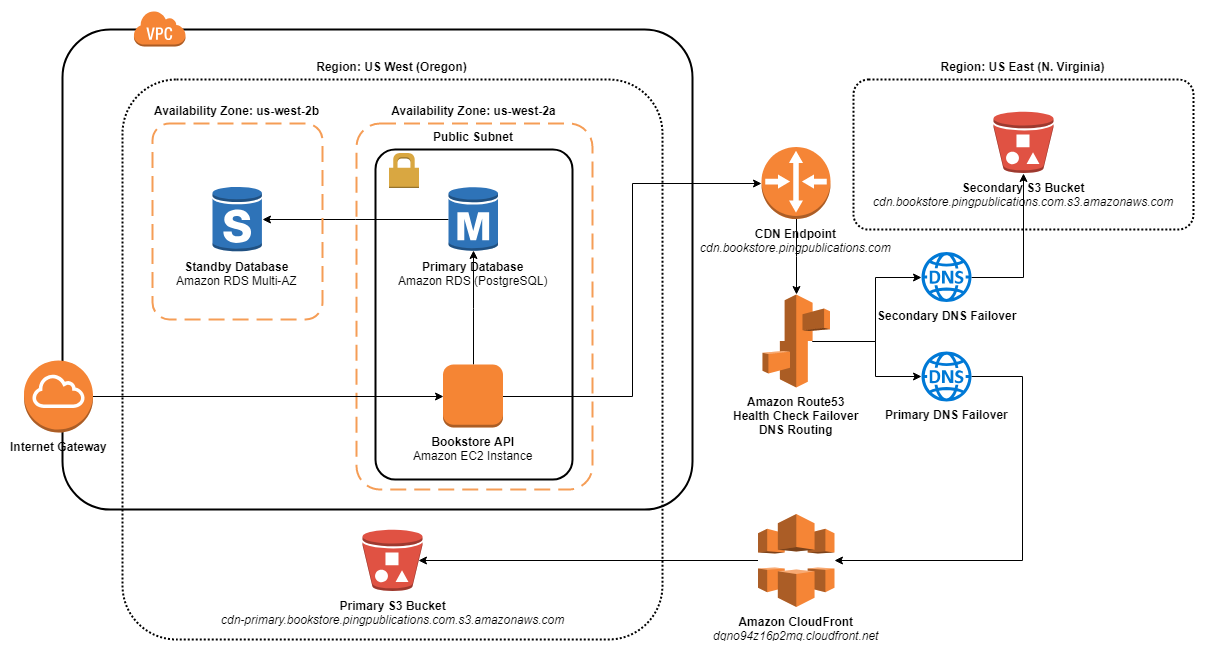 Bookstore App Architecture
Bookstore App Architecture
Database Failure Test
With Multi-AZ configured on the Amazon RDS instance we are now ready to perform a failover test for this critical dependency.
-
Confirm the status and current Availability Zone of the
bookstore-dbinstance with thedescribe-db-instancesCLI command.$ aws rds describe-db-instances --db-instance-identifier bookstore-db --output json --query "DBInstances[*].{Id:DBInstanceIdentifier, AZ:AvailabilityZone, SecondaryAZ:SecondaryAvailabilityZone, Endpoint:Endpoint.Address, Status:DBInstanceStatus}" [ { "SecondaryAZ": "us-west-2b", "Status": "available", "AZ": "us-west-2a", "Id": "bookstore-db", "Endpoint": "bookstore-db.cvajeopcjvda.us-west-2.rds.amazonaws.com" } ] -
Perform a manual reboot via
reboot-db-instance. We’re also forcing a failover with the--force-failoverflag.$ aws rds reboot-db-instance --db-instance-identifier bookstore-db --force-failover --output json --query "DBInstance.{Id:DBInstanceIdentifier, AZ:AvailabilityZone, SecondaryAZ:SecondaryAvailabilityZone, Endpoint:Endpoint.Address, Status:DBInstanceStatus}" { "SecondaryAZ": "us-west-2b", "Status": "rebooting", "AZ": "us-west-2a", "Id": "bookstore-db", "Endpoint": "bookstore-db.cvajeopcjvda.us-west-2.rds.amazonaws.com" } -
Even though the primary instance is currently
Status: rebooting, both the production and secondary Bookstore environments are able to connect todb.bookstore.pingpublications.com, which is pointed to thebookstore-db.cvajeopcjvda.us-west-2.rds.amazonaws.comendpoint.$ curl bookstore.pingpublications.com/books/ | jq [ { "url": "http://bookstore.pingpublications.com/books/1/", "authors": [ { "url": "http://bookstore.pingpublications.com/authors/1/", "birth_date": "1947-09-21", "first_name": "Stephen", "last_name": "King" } ], "publication_date": "1978-09-01", "title": "The Stand" } ]$ curl ec2-54-191-29-110.us-west-2.compute.amazonaws.com/books/ | jq [ { "url": "http://ec2-54-191-29-110.us-west-2.compute.amazonaws.com/books/1/", "authors": [ { "url": "http://ec2-54-191-29-110.us-west-2.compute.amazonaws.com/authors/1/", "birth_date": "1947-09-21", "first_name": "Stephen", "last_name": "King" } ], "publication_date": "1978-09-01", "title": "The Stand" } ]Amazon RDS Multi-AZ automatically switches to the secondary replica on the other Availability Zone and reroutes the endpoint for us.
-
Once the reboot completes, query the
bookstore-dbinstance to confirm that it has swapped the active instance to the other Availability Zone.$ aws rds describe-db-instances --db-instance-identifier bookstore-db --output json --query "DBInstances[*].{Id:DBInstanceIdentifier, AZ:AvailabilityZone, SecondaryAZ:SecondaryAvailabilityZone, Endpoint:Endpoint.Address, Status:DBInstanceStatus}" [ { "SecondaryAZ": "us-west-2a", "Status": "available", "AZ": "us-west-2b", "Id": "bookstore-db", "Endpoint": "bookstore-db.cvajeopcjvda.us-west-2.rds.amazonaws.com" } ] -
Manually confirm the Bookstore API remains connected to the
bookstore-dbinstance replica.$ curl bookstore.pingpublications.com/books/ | jq [ { "url": "http://bookstore.pingpublications.com/books/1/", "authors": [ { "url": "http://bookstore.pingpublications.com/authors/1/", "birth_date": "1947-09-21", "first_name": "Stephen", "last_name": "King" } ], "publication_date": "1978-09-01", "title": "The Stand" } ]
CDN Failure Test
This test ensures that the primary CDN endpoint (cdn.bookstore.pingpublications.com) performs an automatic failover to the secondary Amazon S3 bucket when the Route53 Health Check fails.
-
Retrieve appropriate Health Check
Ids.$ aws route53 list-health-checks --output json { "HealthChecks": [ { "HealthCheckConfig": { "HealthThreshold": 2, "Type": "CALCULATED", "ChildHealthChecks": [ "57a1606e-df1e-43d0-b6d5-e04bf3d789ff", "e4a34329-26c3-4dbe-bec7-4afba94bd487" ], "Inverted": false }, "HealthCheckVersion": 2, "Id": "1b01881d-a658-4d8e-86c9-8d5329d0bfcc" } ] } -
Invert the Health Check, so that a normally healthy value is now considered unhealthy.
$ aws route53 update-health-check --output json --health-check-id 1b01881d-a658-4d8e-86c9-8d5329d0bfcc --inverted { "HealthCheck": { "HealthCheckConfig": { "HealthThreshold": 2, "Type": "CALCULATED", "ChildHealthChecks": [ "57a1606e-df1e-43d0-b6d5-e04bf3d789ff", "e4a34329-26c3-4dbe-bec7-4afba94bd487" ], "Inverted": true }, "HealthCheckVersion": 3, "Id": "1b01881d-a658-4d8e-86c9-8d5329d0bfcc" } } -
After a moment for the Health Check status to update, check the primary CDN endpoint to ensure that it has automatically failed over to the secondary CDN Amazon S3 bucket.
$ curl http://cdn.bookstore.pingpublications.com/static/status.json { "online": true, "cdn": "secondary" } -
Revert the previous Health Check inversion.
$ aws route53 update-health-check --output json --health-check-id 1b01881d-a658-4d8e-86c9-8d5329d0bfcc --no-inverted { "HealthCheck": { "HealthCheckConfig": { "HealthThreshold": 2, "Type": "CALCULATED", "ChildHealthChecks": [ "57a1606e-df1e-43d0-b6d5-e04bf3d789ff", "e4a34329-26c3-4dbe-bec7-4afba94bd487" ], "Inverted": false }, "HealthCheckVersion": 4, "Id": "1b01881d-a658-4d8e-86c9-8d5329d0bfcc" } } -
Verify that the primary CDN endpoint points back to the primary Amazon S3 bucket.
$ curl http://cdn.bookstore.pingpublications.com/static/status.json { "online": true, "cdn": "primary" }
Publish Test Results
Now that both critical dependencies have been tested we’ll publish the results to the entire team, so everyone can keep tabs on the resiliency progress of the project.
In this case, both the Database Failure Test and CDN Failure Test were performed manually within less than 15 minutes. Therefore, we can safely update some of the playbook information created during the prerequisite phase of Resiliency Stage 1 and reduce the critical dependency RTO/RPO targets significantly. Even a conservative estimate of 1 hour is a massive improvement to resiliency and reduction to potential support costs, and we’re only through the second Stage!
| Dependency | Criticality Period | Manual Workaround | RTO | RPO |
|---|---|---|---|---|
| Database | Always | Manual verification of Amazon RDS Multi-AZ secondary instance failover. | 1 | 1 |
| CDN | Always | Manual verification of secondary Amazon S3 bucket failover DNS routing. | 1 | 1 |
Resiliency Stage 2 Completion
Once all critical dependencies have been failure tested and those test results have been disseminated throughout the team then Resiliency Stage 2 is complete! Your system should now have well-defined recovery playbooks and been manually tested for both failover and critical dependency failures. In Chaos Engineering Through Staged Resiliency - Stage 3 we’ll look at the transition into automating some of these tests and performing them at regular intervals.