Migrating to the Cloud Is Chaotic. Embrace It.
Why organizations planning to migrate to the cloud should embrace Chaos Engineering as a thoughtful strategy to avoid pain down the road.
Migrating to the cloud is an intimidating prospect and understandably so – there’s a lot that will change in your systems from on-prem to the cloud, and changes can mean instability in your systems.
How can you ensure your software will be safe after migrating to the cloud? How do you combat the cloud’s chaotic nature while ensuring a resilient and stable system? By intentionally inducing Chaos well before migration begins.
It sounds counter-intuitive to perform Chaos Engineering while your team is actively migrating to the cloud. Wouldn’t that just add failure and slow down an already challenging process? The reality is that when you’re migrating to the cloud Chaos Engineering is the best way to be confident that you’ve tested how your new system will behave once you switch traffic over. By performing Chaos Experiments on the environment you’re migrating into, you’ll identify weaknesses with plenty of time to mitigate them.
In 2016, groups from the University of Chicago and Surya University jointly published an in-depth cloud outage study that examined the causes of service outages among 32 of the most popular Internet services between 2009 and 2015. This post will go into a number of these outages and provide tutorials to run Chaos Experiments and proactively identify potential issues before they turn into production outages.
The study found that the majority of unplanned outages (16%) are caused by failures during upgrade and migration processes.
Managing Heavy CPU Load
An overloaded CPU can quickly create bottlenecks and cause failures within most architectures. In a distributed cloud environment, instability in a single system can quickly cascade into problems elsewhere down the chain. Proper CPU resilience testing helps to determine which existing systems are currently resilient to a CPU failure, and which need to be prioritized for upgrade and migration necessary to maintain a stable stack.
Why It Matters: Hotmail & Outlook (2013)
Microsoft’s customer migration from Hotmail to the new Outlook.com was generally executed without a hitch. Unfortunately, on March 12th, 2013 a failed firmware upgrade caused a 16+ hour outage for some customers trying to access SkyDrive, Hotmail, and Outlook.com services.
Microsoft reported that the firmware update “failed […] in an unexpected way,” but did not provide any additional details on the root cause. However, this failure resulted in rapid, substantial temperature spikes within the datacenter. The increase in temperature triggered automatic safeguards for a large portion of the servers within the datacenter. Consequently, the safeguards prevented mailbox access for affected customers, and also prevented automatic failover processes from performing their normal duties.
Without additional details on the root cause and the specific impacts, we can only speculate, but a temperature spike points toward a dramatic spike in CPU load for some servers within the datacenter. In this particular instance, it’s possible that pre-emptive Chaos Engineering may have allowed engineers to simulate similar heavy CPU load scenarios.
Performing a CPU Attack with Gremlin
A Gremlin CPU Attack consumes 100% of the specified CPU cores on the target system. The CPU Attack is a great way to test the stability of the targeted machine – along with its critical dependencies – when the CPU is overloaded.
Prerequisites
- Install Gremlin on the target machine.
- Retrieve your Gremlin API Token.
A Gremlin API CPU Attack accepts the following arguments.
| Short Flag | Long Flag | Purpose |
|---|---|---|
-c |
--cores |
Number of CPU cores to attack. |
-l |
--length |
Attack duration (in seconds). |
Most Gremlin API calls accept a JSON body payload, which specifies critical arguments. In all the following examples you’ll be creating a local attacks/<attack-name>.json file to store the API attack arguments. You’ll then pass those arguments along to the API request.
-
On your local machine, start by creating the
attacks/cpu.jsonfile and paste the following JSON into it. This will attack a single core for30seconds.{ "command": { "type": "cpu", "args": ["-c", "1", "-l", "30"] }, "target": { "type": "Random" } } -
Create the new Attack by passing the JSON from
attacks/cpu.jsonto thehttps://api.gremlin.com/v1/attacks/newAPI endpoint.curl -H "Content-Type: application/json" -H "Authorization: $GREMLIN_API_TOKEN" https://api.gremlin.com/v1/attacks/new -d "@attacks/cpu.json" -
The Gremlin Web UI also shows the Attack that was created.
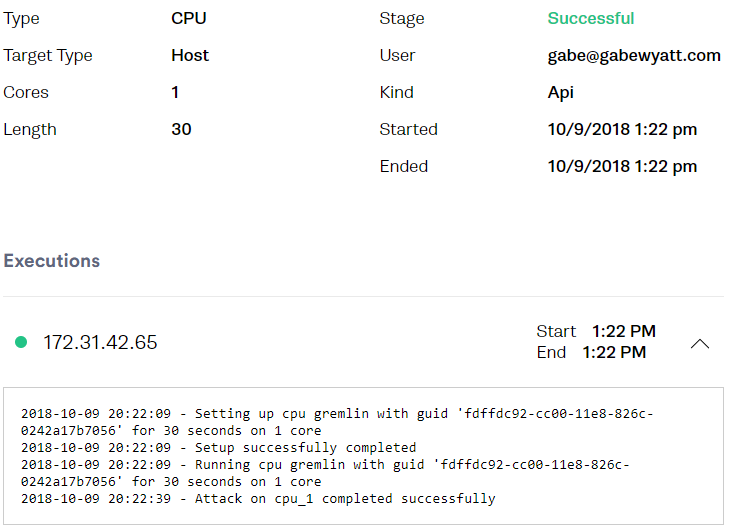
-
On the targeted machine you’ll see that one CPU core is maxed out.
htop
If you wish to attack a specific Client just change the target : type argument value to "Exact" and add the target : exact field with a list of target Clients. A Client is identified on Gremlin as the GREMLIN_IDENTIFIER for the instance, which can also be specified in a local environment variable when running the gremlin init command.
{
"command": {
"type": "cpu",
"args": ["-c", "1", "-l", "30"]
},
"target": {
"type": "Exact",
"exact": ["aws-nginx"]
}
}
Handling Storage Disk Limitations
Migrating to a new system frequently requires moving volumes across disks and to other cloud-based storage layers. It’s vital to determine if the new storage system can handle the increase in volume that the migration will require. Additionally, to properly test the resilience of the system you’ll also want to test how the system reacts when volumes are overburdened or unavailable.
Why It Matters: Instapaper (2017)
In February 2017 the popular web content bookmarking service Instapaper suffered a service outage due to a 2 TB file size limit within Instapaper’s Amazon RDS MySQL instance.
This issue was unknown to Instapaper ever since their migration to AWS in 2013. At that time, they migrated their database to MySQL on Amazon RDS, which was using a slightly outdated version of MySQL that enforced the 2 TB file size limit. Even after attempting to upgrade to newer hardware and a newer MySQL version in March 2015, the original instance that contained the 2 TB limit was replicated, thereby retaining the underlying problem.
Eventually, their database finally hit that limit in early 2017 and caused a day+ service outage. As Instapaper points out in their postmortem, it was difficult for the team to be aware of this limitation and potential issue ahead of time. However, this unfortunate event illustrates the importance of properly testing data storage systems prior to migration.
Performing a Disk Attack with Gremlin
Gremlin’s Disk Attack rapidly consumes disk space on the targeted machine, allowing you to test the resiliency of that machine and other related systems when unexpected disk failures occur.
Prerequisites
- Install Gremlin on the target machine.
- Retrieve your Gremlin API Token.
A Gremlin API Disk Attack accepts the following arguments.
| Short Flag | Long Flag | Purpose |
|---|---|---|
-b |
--block-size |
The block size (in kilobytes) that are written. |
-d |
--dir |
The directory that temporary files will be written to. |
-l |
--length |
Attack duration (in seconds). |
-p |
--percent |
The percentage of the volume to fill. |
-w |
--workers |
The number of disk-write workers to run concurrently. |
-
On your local machine, start by creating the
attacks/disk.jsonfile and paste the following JSON into it. Be sure to change your target Client. This attack will fill95%of the volume over the course of a60-secondattack using2workers.{ "command": { "type": "disk", "args": ["-d", "/tmp", "-l", "60", "-w", "2", "-b", "4", "-p", "95"] }, "target": { "type": "Exact", "exact": ["aws-nginx"] } } -
(Optional) Check the current disk usage on the target machine.
df -H # OUTPUT Filesystem Size Used Avail Use% Mounted on /dev/xvda1 8.3G 1.4G 6.9G 17% / -
Create the new Disk Attack by passing the JSON from
attacks/disk.jsonto thehttps://api.gremlin.com/v1/attacks/newAPI endpoint.curl -H "Content-Type: application/json" -H "Authorization: $GREMLIN_API_TOKEN" https://api.gremlin.com/v1/attacks/new -d "@attacks/disk.json" -
The Gremlin Web UI now shows the Attack that was created.
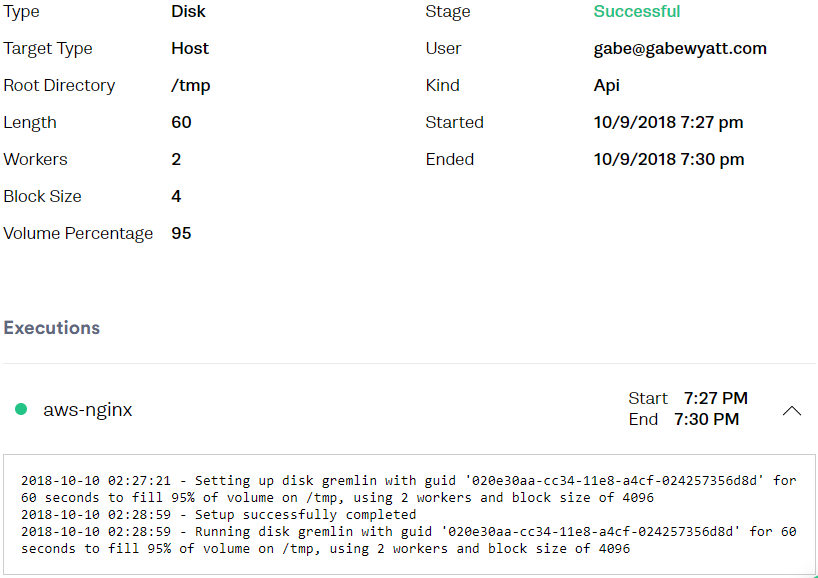
-
Check the attack target’s current disk space, which will soon reach the specified percentage before Gremlin rolls back and returns the disk to the original state.
df -H # OUTPUT Filesystem Size Used Avail Use% Mounted on /dev/xvda1 8.3G 7.9G 396M 96% /
Evaluating Network Resiliency
While the majority of Internet service outages are caused by failures during migration and upgrade procedures, the aforementioned Why Does the Cloud Stop Computing?
Lessons from Hundreds of Service Outages study found that network problems are the second most common cause and account for some 15% of service outages. Even architectures designed with network redundancies can experience multiple, cumulative network failures without proper testing and experimentation. Moreover, most modern software relies on external networks to some degree, which means a network outage completely outside of your control could cause a failure to propagate throughout your system.
Why It Matters: Microsoft Office 365 (2013)
On February 1st, 2013 a change to the Microsoft Online edge network prevented some internet traffic from reaching the Microsoft Office 365 service, which prevented customers from accessing Exchange and SharePoint services for a few hours. While the incident report doesn’t explicitly name the underlying change that caused the problem, it does state that a procedural error was unintentionally and automatically propagated to multiple devices within the Microsoft Online network, which “caused incorrect routing for a portion of the inbound internet traffic.” Additionally, affected customers were unable to access administrative services within the Service Health Dashboard (SHD) provided by Microsoft, but the backup process intended to provide support to customers that were unable to access the SHD did not work as well as expected.
While this overall incident only lasted a few hours and affected a small subset of customers, it illustrates the importance of proper network resiliency testing prior to and during system migrations. Chaos Experiments that cause networking failures – such as creating a black hole so certain traffic is halted – are a great way to test system stability under these unexpected conditions.
Performing a Black Hole Attack with Gremlin
A Black Hole Attack temporarily drops all traffic based on the parameters of the attack. You can use a Black Hole Attack to test routing protocols, loss of communication to specific hosts, port-based traffic, network device failure, and much more.
Prerequisites
- Install Gremlin on the target machine.
- Retrieve your Gremlin API Token.
A Gremlin API Black Hole Attack accepts the following arguments.
| Short Flag | Long Flag | Purpose |
|---|---|---|
-d |
--device |
Network device through which traffic should be affected. Defaults to the first device found. |
-h |
--hostname |
Outgoing hostnames to affect. Optionally, you can prefix a hostname with a caret (^) to whitelist it. It is recommended to include ^api.gremlin.com in the whitelist. |
-i |
--ipaddress |
Outgoing IP addresses to affect. Optionally, you can prefix an IP with a caret (^) to whitelist it. |
-l |
--length |
Attack duration (in seconds). |
-n |
--ingress_port |
Only affect ingress traffic to these destination ports. Ranges can also be specified (e.g. 8080-8085). |
-p |
--egress_port |
Only affect egress traffic to these destination ports. Ranges can also be specified (e.g. 8080-8085). |
-P |
--ipprotocol |
Only affect traffic using this protocol. |
-
Start by performing a test to establish a baseline. The following command tests the response time of a request to
example.com(which has an IP address of93.184.216.34).$ time curl -o /dev/null 93.184.216.34 # OUTPUT real 0m0.025s user 0m0.009s sys 0m0.000s -
On your local machine, create the
attacks/blackhole.jsonfile and paste the following JSON into it. Set your target Client as necessary. This attack creates a30-secondblack hole that drops traffic to the93.184.216.34IP address.{ "command": { "type": "blackhole", "args": ["-l", "30", "-i", "93.184.216.34", "-h", "^api.gremlin.com"] }, "target": { "type": "Exact", "exact": ["aws-nginx"] } } -
Execute the Black Hole Attack by passing the JSON from
attacks/blackhole.jsonto thehttps://api.gremlin.com/v1/attacks/newAPI endpoint.curl -H "Content-Type: application/json" -H "Authorization: $GREMLIN_API_TOKEN" https://api.gremlin.com/v1/attacks/new -d "@attacks/blackhole.json" -
On the target machine run the same timed
curltest as before. It now hangs for approximately30seconds until the black hole has been terminated and a response is finally received.$ time curl -o /dev/null 93.184.216.34 # OUTPUT real 0m31.623s user 0m0.013s sys 0m0.000s -
You can also view the Attack on the Gremlin Web UI to confirm it functioned properly.
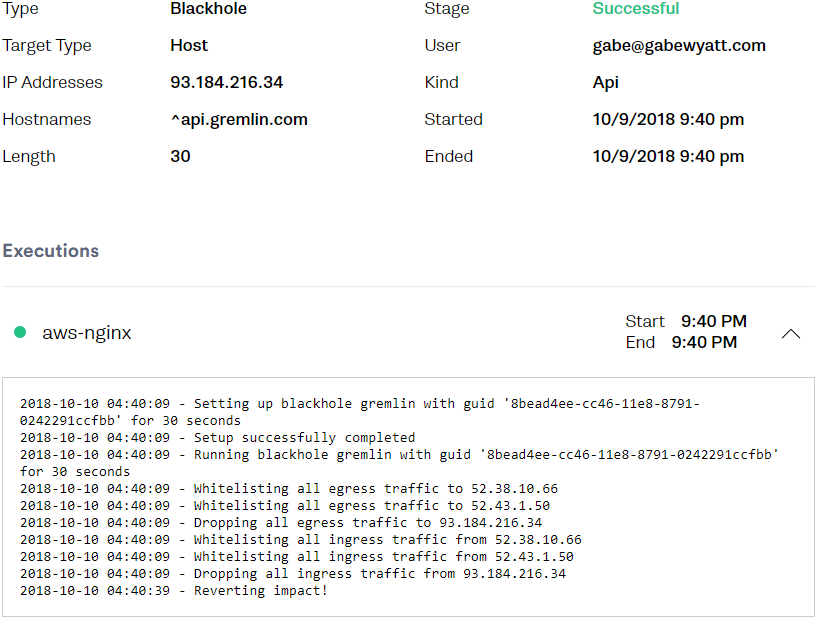
Proper Memory Management
While most commonly-used cloud platforms provide auto-balancing and scaling services, it’s impossible to rely solely on these technologies to ensure your migrated software will remain stable and responsive. Memory management is a crucial part of maintaining a healthy and inexpensive cloud stack. An improper configuration or poorly tested system may not necessarily cause a system failure or outage, but even a tiny memory issue can add up to thousands of dollars in extra support costs.
Performing Chaos Engineering before, during, and after cloud migration lets you test system failures when instances, containers, or nodes run out of memory. This testing ensures your stack remains active and fully functional when an unexpected memory leak occurs.
Why It Matters: Google Docs (2011)
In early September 2011 Google Docs suffered a widespread, hour-long outage that prevented the majority of customers from accessing documents, drawings, lists, and App Scripts. As Google later reported, the incident was caused by a change that exposed a memory leak that only occurred under heavy load. The lookup service that tracks Google Doc modifications wasn’t properly recycling memory, which eventually caused those machines to restart. Redundancy systems immediately picked up the slack from these now-offline lookup service machines, but the excessive load caused the replacement machines to run out of memory even faster. Eventually, the servers couldn’t handle the number of requests that were backed up, which led to the outage.
The Google engineering team was quick to diagnose the issue and roll out a fix within an hour of the first automated alert. Unfortunately, Google engineers were unaware of the root cause because it only occurred while the system was heavily loaded, which shows the importance of expressly testing system resilience when memory usage spikes.
Performing a Memory Attack with Gremlin
A Gremlin Memory Attack consumes memory on the targeted machine, making it easy to test how that system and other dependencies behave when memory is unavailable.
Prerequisites
- Install Gremlin on the target machine.
- Retrieve your Gremlin API Token.
A Gremlin API Memory Attack accepts the following arguments.
| Short Flag | Long Flag | Purpose |
|---|---|---|
-g |
--gigabytes |
The amount of memory (in GB) to allocate. |
-l |
--length |
Attack duration (in seconds). |
-m |
--megabytes |
The amount of memory (in MB) to allocate. |
-
(Optional) On the target machine check the current memory usage to establish a baseline prior to executing the attack.
htop
-
On your local machine create an
attacks/memory.jsonfile and paste the following JSON into it, ensuring you change your target Client. This attack will consume up to0.75 GBof memory for a total of30seconds.{ "command": { "type": "memory", "args": ["-l", "30", "-g", "0.75"] }, "target": { "type": "Exact", "exact": ["aws-nginx"] } } -
Launch the Memory Attack by passing the JSON from
attacks/memory.jsonto thehttps://api.gremlin.com/v1/attacks/newAPI endpoint.curl -H "Content-Type: application/json" -H "Authorization: $GREMLIN_API_TOKEN" https://api.gremlin.com/v1/attacks/new -d "@attacks/memory.json" -
That additional memory is now consumed on the target machine.
htop
-
As always, you can view the Attack within the Gremlin Web UI.
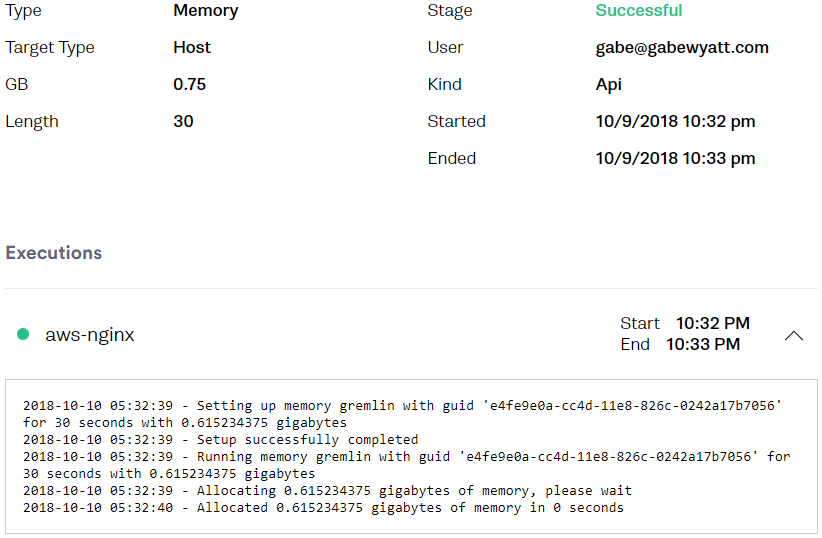
Troubleshooting IO Bottlenecks
Due to the proliferation of automatic monitoring and elastic scaling, IO failure may seem like one of the least likely problems within a cloud architecture. However, even when IO failure isn’t necessarily the root cause of an outage it is often the result of another issue. IO failure typically triggers a negative cascading effect throughout the many other dependent systems. Moreover, since IO failure is often considered an unlikely event, it’s more common for cloud-based stacks to be particularly vulnerable to IO-induced outages.
Why It Matters: Amazon EC2, EBS, and RDS (2011)
Over the course of about a week in April 2011, Amazon EC2 customers suffered a significant service outage when a high percentage of Amazon Elastic Block Store (EBS) volumes within a single Availability Zone in the US East Region became “stuck” – unable to perform read and write operations. Other service instances attempting to access these “stuck” EBS volumes also became “stuck” while trying to read or write to the volumes. In turn, this degraded EBS cluster performance and increased latencies and error rates for EBS API calls across the entire US East Region.
Understanding the root cause of this outage and everything that was impacted requires a bit of understanding of how Amazon EBS functions. Normally, an EBS cluster is comprised of a set of EBS nodes that automatically store EBS volume replicas and serve as fast failover redundancies. If any single EBS volume is out of sync or is unavailable the peer-to-peer failover quickly provisions a new replica to replace the unavailable copy. EBS nodes communicate over two networks. The primary network handles high bandwidth connections for normal node-to-node, EC2, and control plane service communications. The secondary network is a backup network to provide overflow capacity for data replication, but this secondary network is not intended to handle the traffic level of the primary network.
The outage stemmed from an improperly executed traffic shift while performing a configuration change to the primary network. Traffic was incorrectly moved onto the low-capacity secondary network. This had the effect of isolating many of the EBS nodes within the impacted Availability Zone, severing their connections to their replicas.
While the issue was quickly noticed and addressed, once traffic was reverted back to the primary network the affected EBS nodes swarmed the EBS cluster trying to find available server space to re-mirror data. This overloaded the cluster and quickly consumed all free capacity, thereby leaving many EBS nodes in a “stuck” state.
In total, around 13% of all volumes in the affected Availability Zone were in a “stuck” state.
The full incident summary report is a fascinating read if you have the time. This incident presents a solid real-world example of the dramatic and costly impacts that even an initially minor IO failure can have on a large, distributed system.
Performing an IO Attack with Gremlin
Gremlin’s IO Attack performs rapid read and/or write actions on the targeted system volume.
Prerequisites
- Install Gremlin on the target machine.
- Retrieve your Gremlin API Token.
A Gremlin API IO Attack accepts the following arguments.
| Short Flag | Long Flag | Purpose |
|---|---|---|
-c |
--block-count |
The number of blocks read or written by workers. |
-d |
--dir |
The directory that temporary files will be written to. |
-l |
--length |
Attack duration (in seconds). |
-m |
--mode |
Specifies if workers are in read (r), write (w), or read+write (rw) mode. |
-s |
--block-size |
Size of blocks (in KB) that are read or written by workers. |
-w |
--workers |
The number of concurrent workers. |
-
On your local machine create an
attacks/io.jsonfile and paste the following JSON into it. Change the target Client as necessary. This IO Attack creates two workers that will perform both reads and writes during the45-secondattack.{ "command": { "type": "io", "args": ["-l", "45", "-d", "/tmp", "-w", "2", "-m", "rw", "-s", "4", "-c", "1"] }, "target": { "type": "Exact", "exact": ["aws-nginx"] } } -
Launch the IO Attack by passing the JSON from
attacks/io.jsonto thehttps://api.gremlin.com/v1/attacks/newAPI endpoint.curl -H "Content-Type: application/json" -H "Authorization: $GREMLIN_API_TOKEN" https://api.gremlin.com/v1/attacks/new -d "@attacks/io.json" -
On the target machine verify that the attack is running and that IO is currently overloaded.
$ sudo iotop -aoP # OUTPUT Total DISK READ : 0.00 B/s | Total DISK WRITE : 3.92 M/s Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 15.77 M/s PID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 323 be/3 root 0.00 B 68.00 K 0.00 % 71.28 % [jbd2/xvda1-8] 20030 be/4 gremlin 0.00 B 112.15 M 0.00 % 17.11 % gremlin attack io -l 45 -d /tmp -w 2 -m rw -s 4 -c 1 -
You can also view the Attack within the Gremlin Web UI.
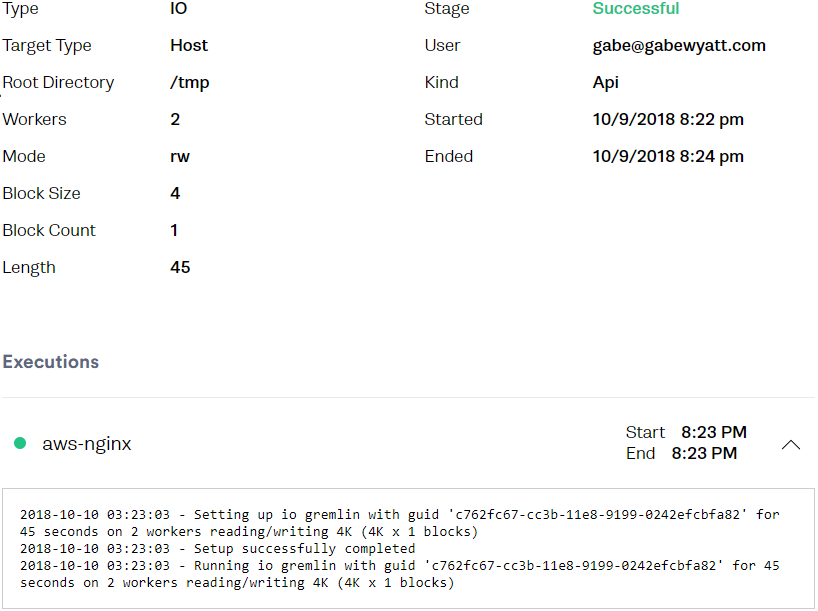
What Comes Next?
This article explored a number of common issues and outages related to failed migrations and upgrade procedures. As impactful and expensive as those outages may have been, their existence shouldn’t dissuade you from making the move to the cloud. A distributed architecture allows you to enjoy faster release cycles and, in general, increased developer productivity.
Instead, the occurrence of migration issues for even the biggest organizations in the industry illustrates the necessity of proper resilience testing. Chaos Engineering is a critical piece of that finished and fully-resilient puzzle. Planning ahead and running Chaos Experiments on your systems, both prior to and during migration, will help ensure you’re creating the most stable, robust, and resilient system possible.