Chaos Engineering Through Staged Resiliency - Stage 3
Performing occasional, manual resiliency testing is useful, but your system must be automatically and frequently tested to provide any real sense of stability. In Chaos Engineering Through Staged Resiliency - Stage 2 we focused on critical dependency failure testing in non-production environments. To work through Resiliency Stage 3 your team will need to begin automating these test and experiments. This allows the testing frequency to improve dramatically and reduces the reliance on manual processes.
Prerequisites
- Creation and agreement on Disaster Recovery and Dependency Failover Playbooks.
- Completion of Resiliency Stage 1.
- Completion of Resiliency Stage 2.
Perform Frequent, Semi-Automated Tests
There’s no more putting it off – it’s time to begin automating your testing procedures. During this third Resiliency Stage, the team should aim to automate as much of the resiliency testing process as reasonably possible. The overall goal of this stage isn’t to finalize automation, but to work toward a regular cadence of testing. The frequency of each test is up to the team, but once established it’s critical that the schedule is maintained and automation handles at least some of the testing process.
If the team isn’t already doing so, this is a prime opportunity to introduce Chaos Engineering tools. These tools empower the team to intelligently create controlled experiments that can be executed precisely when necessary. For example, Gremlin attacks can be scheduled to execute on certain days of the week and within a specified window of time.
Execute a Resiliency Experiment in Production
Resiliency experiments in non-production are beneficial, but a system is never truly being properly tested unless you’re willing to perform experiments in production. Use of internal or third-party Chaos Engineering tools can help with the process of executing a resiliency experiment in production. A tool that configures and executes a given experiment can be used to repeat that experiment over and over, without introducing any issues that may normally be introduced due to human intervention. As experiments are performed and the results evaluated, observability will improve, playbooks are updated, and overall support costs are reduced.
Publish Test Results
As you’ve been doing thus far, you must continue publishing test results to the entire team. This step is especially critical now that experiments are being performed in production.
Resiliency Stage 3: Implementation Example
How to Automate Blue/Green Instance Failover in AWS
The blue/green deployment for the Bookstore application provides two identical production environment instances of the system. However, if the currently active instance fails we still have to manually swap DNS records from blue to green (or vice versa). In order to meet the requirement of executing a resiliency experiment in production, we need to automate this failover process.
-
Create a metric alarm within Amazon CloudWatch.
$ aws cloudwatch put-metric-alarm --output json --cli-input-json '{ "ActionsEnabled": true, "AlarmActions": [ "arn:aws:sns:us-west-2:532151327118:PingPublicationsSNS" ], "AlarmDescription": "Bookstore API (Blue) instance failure.", "AlarmName": "bookstore-api-blue-StatusCheckFailed", "ComparisonOperator": "GreaterThanOrEqualToThreshold", "DatapointsToAlarm": 1, "Dimensions": [ { "Name": "InstanceId", "Value": "i-0ab55a49288f1da24" } ], "EvaluationPeriods": 1, "MetricName": "StatusCheckFailed", "Namespace": "AWS/EC2", "Period": 60, "Statistic": "Maximum", "Threshold": 1.0, "TreatMissingData": "breaching" }'The above configuration checks the
StatusCheckFailedmetric once a minute, which determines if either the Amazon EC2 system or the specific EC2 instance has failed. We have to setTreatMissingDatatobreachingso that the absence of data will trigger anALARMstate (otherwise, the instance can bestoppedorterminated, but theStatusCheckwill succeed).The
Dimensionsarray ensures thisbookstore-api-blue-StatusCheckFailedalarm only checks against thebookstore-api-blueinstance, and theAlarmActionsspecifies an Amazon SNS ARN to push an alert to when the alarm is triggered. -
Next, create an Amazon Route53 Health Check that uses the
bookstore-api-blue-StatusCheckFailedAmazon CloudWatch alarm for itshealthy/unhealthydetermination.$ aws route53 create-health-check --caller-reference bookstore-api-blue-health-check --output json --health-check-config '{ "InsufficientDataHealthStatus": "Unhealthy", "Type": "CLOUDWATCH_METRIC", "AlarmIdentifier": { "Region": "us-west-2", "Name": "bookstore-api-blue-StatusCheckFailed" }, "Inverted": false }' { "HealthCheck": { "HealthCheckConfig": { "InsufficientDataHealthStatus": "Unhealthy", "Type": "CLOUDWATCH_METRIC", "AlarmIdentifier": { "Region": "us-west-2", "Name": "bookstore-api-blue-StatusCheckFailed" }, "Inverted": false }, "CallerReference": "bookstore-api-blue-health-check", "HealthCheckVersion": 1, "Id": "119e6884-3685-4e5a-9520-44cebae6c734", "CloudWatchAlarmConfiguration": { "EvaluationPeriods": 1, "Dimensions": [ { "Name": "InstanceId", "Value": "i-0ab55a49288f1da24" } ], "Namespace": "AWS/EC2", "Period": 60, "ComparisonOperator": "GreaterThanOrEqualToThreshold", "Statistic": "Maximum", "Threshold": 1.0, "MetricName": "StatusCheckFailed" } }, "Location": "https://route53.amazonaws.com/2013-04-01/healthcheck/119e6884-3685-4e5a-9520-44cebae6c734" }TIP: To reduce AWS costs we’re using a 60-second metric evaluation interval here, but in a more demanding application this
Periodshould be significantly shorter. -
Retrieve the
Idfor thepingpublications.comAmazon Route53 hosted zone.$ aws route53 list-hosted-zones --output json { "HostedZones": [ { "ResourceRecordSetCount": 5, "CallerReference": "303EC092-EDA3-C2B7-822E-5E609CA718A3", "Config": { "PrivateZone": false }, "Id": "/hostedzone/Z2EHK3FAEUNRMI", "Name": "pingpublications.com." } ] } -
Create a pair of Amazon Route53
Type: ADNS record sets that will perform aFailoverrouting policy from thebookstore-api-blueto thebookstore-api-greenproduction environment. Therefore, even in the event that the blue instance fails the above health check, thebookstore.pingpublications.comendpoint will always point to an active production instance.$ aws route53 change-resource-record-sets --hosted-zone-id /hostedzone/Z2EHK3FAEUNRMI --output json --change-batch '{ "Comment": "Adding bookstore.pingpublications.com failover.", "Changes": [ { "Action": "CREATE", "ResourceRecordSet": { "Name": "bookstore.pingpublications.com.", "Type": "A", "SetIdentifier": "bookstore-Primary", "Failover": "PRIMARY", "TTL": 60, "ResourceRecords": [ { "Value": "54.213.54.171" } ], "HealthCheckId": "119e6884-3685-4e5a-9520-44cebae6c734" } }, { "Action": "CREATE", "ResourceRecordSet": { "Name": "bookstore.pingpublications.com.", "Type": "A", "SetIdentifier": "bookstore-Secondary", "Failover": "SECONDARY", "TTL": 60, "ResourceRecords": [ { "Value": "52.11.79.9" } ] } } ] }' { "ChangeInfo": { "Status": "PENDING", "Comment": "Adding bookstore.pingpublications.com failover.", "SubmittedAt": "2018-11-15T01:54:15.785Z", "Id": "/change/C1XJ0G2FTPLYDO" } } -
Double-check that the two failover record sets have been created.
$ aws route53 list-resource-record-sets --hosted-zone-id /hostedzone/Z2EHK3FAEUNRMI --output json { "ResourceRecordSets": [ { "HealthCheckId": "119e6884-3685-4e5a-9520-44cebae6c734", "Name": "bookstore.pingpublications.com.", "Type": "A", "Failover": "PRIMARY", "ResourceRecords": [ { "Value": "54.213.54.171" } ], "TTL": 60, "SetIdentifier": "bookstore-Primary" }, { "Name": "bookstore.pingpublications.com.", "Type": "A", "Failover": "SECONDARY", "ResourceRecords": [ { "Value": "52.11.79.9" } ], "TTL": 60, "SetIdentifier": "bookstore-Secondary" } ] }
Verifying Automated Instance Failover
To test the failover process for the Bookstore API application instances we’ll use a Gremlin Shutdown Attack. This attack will temporarily shutdown the bookstore-api-blue Amazon EC2 instance.
-
Verify the current status of the Bookstore API by checking the
bookstore.pingpublications.com/version/endpoint.$ curl bookstore.pingpublications.com/version/ | jq { "environment": "bookstore-api-blue", "version": 7 }This shows what app version is running and confirms that the endpoint is pointing to the
bookstore-api-blueAmazon EC2 instance. -
Run a Gremlin Shutdown Attack targeting the
bookstore-api-blueClient. Check out the Gremlin Help documentation for more details on creating attacks with Gremlin’s Chaos Engineering tools. -
After a moment the Amazon CloudWatch
bookstore-api-blue-StatusCheckFailedAlarm triggers, thereby causing thebookstore-api-blue-healthyAmazon Route53 health check to fail. This automatically triggers the DNS failover created previously, which points the primarybookstore.pingpublications.comendpoint to thegreenEC2 production environment. Verify this failover has automatically propagated by checking the/version/endpoint once again.$ curl bookstore.pingpublications.com/version/ | jq { "environment": "bookstore-api-green", "version": 7 }
How to Generate Custom AWS Metrics
Automating critical dependency failure tests often requires a way to simulate the failure of critical dependencies if those dependencies are third-party and therefore out of our control. This is the case with the Bookstore app that relies on Amazon S3 and Amazon RDS for its CDN and database services, respectively. Tools like Gremlin can help with this task. Running a Gremlin Blackhole Attack on the Bookstore API environment can block all network communication between the API instance and specified endpoints, including those for the CDN and database.
However, AWS EC2 instances don’t have any built-in capability to monitor the connectivity between said instance and another arbitrary endpoint. Therefore, the solution is to create some custom metrics that will effectively measure the “health” of the connection between the Bookstore API instance and its critical dependencies.
While AWS provides many built-in metrics, creating custom metrics requires that you explicitly generate all the relevant data for said metric. For this reason, a custom metric is little more than a combination of a metric name and list of dimensions, which are used as key/value pairs to distinguish and categorize metrics. For our purposes here we’re creating simple metrics that act as a health monitor for each critical dependency.
-
We start by creating a couple of bash scripts within our application code repository. These scripts are executed from the Bookstore API instances.
#!/bin/bash # ~/apps/bookstore_api/metrics/db-connectivity.sh INSTANCE_ID="$(ec2metadata --instance-id)" TAG_NAME="$(/home/ubuntu/.local/bin/aws ec2 describe-tags --filter "Name=resource-id,Values=$INSTANCE_ID" "Name=key,Values=Name" --query "Tags[*].Value" --output text)" while sleep 10 do if nc -zv -w 5 db.bookstore.pingpublications.com 5432 2>&1 | grep --line-buffered -i succeeded; then /home/ubuntu/.local/bin/aws cloudwatch put-metric-data --metric-name db-connectivity --namespace Bookstore --dimensions Host=$TAG_NAME --value 1 else echo "Connection to db.bookstore.pingpublications.com 5432 port [tcp/postgresql] failed!" /home/ubuntu/.local/bin/aws cloudwatch put-metric-data --metric-name db-connectivity --namespace Bookstore --dimensions Host=$TAG_NAME --value 0 fi done#!/bin/bash # ~/apps/bookstore_api/metrics/cdn-connectivity.sh INSTANCE_ID="$(ec2metadata --instance-id)" TAG_NAME="$(/home/ubuntu/.local/bin/aws ec2 describe-tags --filter "Name=resource-id,Values=$INSTANCE_ID" "Name=key,Values=Name" --query "Tags[*].Value" --output text)" while sleep 10 do if nc -zv -w 5 cdn.bookstore.pingpublications.com 80 2>&1 | grep --line-buffered -i succeeded; then /home/ubuntu/.local/bin/aws cloudwatch put-metric-data --metric-name cdn-connectivity --namespace Bookstore --dimensions Host=$TAG_NAME --value 1 else echo "Connection to cdn.bookstore.pingpublications.com 80 port [tcp/http] failed!" /home/ubuntu/.local/bin/aws cloudwatch put-metric-data --metric-name cdn-connectivity --namespace Bookstore --dimensions Host=$TAG_NAME --value 0 fi doneTo check the connectivity for the database or CDN endpoint we first retrieve the Amazon EC2 instance Id and, from that, get the
Nametag value, which is passed as theHostdimension when creating our metric. ThisHostvalue specifies which environment (blue/green) is being evaluated.These scripts use netcat to check the current network connectivity between the instance and the primary critical dependency endpoint. This check is performed every
10 seconds. The AWS CLI then generates metric data for thedb-connectivityandcdn-connectivitymetrics, passing a value of1if the connection succeeded and0for a failure. -
Create
systemdservice configuration files so the bash scripts will be executed and remain active.-
Start by creating the
bookstore-db-connectivityservice and pointing theExecStartcommand to thedb-connectivity.shfile.sudo nano /etc/systemd/system/bookstore-db-connectivity.service[Unit] Description=Bookstore Database Connectivity Service After=network.target [Service] Type=simple User=ubuntu Group=ubuntu WorkingDirectory=/home/ubuntu ExecStart=/home/ubuntu/apps/bookstore_api/metrics/db-connectivity.sh Restart=always [Install] WantedBy=multi-user.target -
Do the same for the CDN.
sudo nano /etc/systemd/system/bookstore-cdn-connectivity.service[Unit] Description=Bookstore CDN Connectivity Service After=network.target [Service] Type=simple User=ubuntu Group=ubuntu WorkingDirectory=/home/ubuntu ExecStart=/home/ubuntu/apps/bookstore_api/metrics/cdn-connectivity.sh Restart=always [Install] WantedBy=multi-user.target
-
-
Set permissions such that both service target scripts are executable.
chmod +x /home/ubuntu/apps/bookstore_api/metrics/db-connectivity.sh && chmod +x /home/ubuntu/apps/bookstore_api/metrics/cdn-connectivity.sh -
Enable both services and either reboot the instance or manually start the services.
sudo systemctl enable bookstore-db-connectivity && sudo systemctl enable bookstore-cdn-connectivitysudo systemctl start bookstore-db-connectivity && sudo systemctl start bookstore-cdn-connectivity -
Verify that both services are active.
$ sudo systemctl status bookstore-db-connectivity.service Loaded: loaded (/etc/systemd/system/bookstore-db-connectivity.service; disabled; vendor preset: enabled) Active: active (running) since Mon 2018-11-17 12:02:19 UTC; 2min 3s ago Nov 17 12:02:42 bookstore-api-green systemd[1]: Started Bookstore Database Connectivity Service. Nov 17 12:02:42 bookstore-api-green db-connectivity.sh[24683]: Connection to db.bookstore.pingpublications.com 5432 port [tcp/postgresql] succeeded!$ sudo systemctl status bookstore-cdn-connectivity Loaded: loaded (/etc/systemd/system/bookstore-cdn-connectivity.service; disabled; vendor preset: enabled) Active: active (running) since Mon 2018-11-17 12:02:19 UTC; 20s ago Nov 17 12:02:19 bookstore-api-green systemd[1]: Started Bookstore CDN Connectivity Service. Nov 17 12:02:31 bookstore-api-green cdn-connectivity.sh[24695]: Connection to cdn.bookstore.pingpublications.com 80 port [tcp/http] succeeded! -
Create Amazon CloudWatch Alarms based on the four generated metrics. These alarms check for a connectivity failure within the last two minutes.
aws cloudwatch put-metric-alarm --output json --cli-input-json '{ "ActionsEnabled": true, "AlarmActions": [ "arn:aws:sns:us-west-2:532151327118:PingPublicationsSNS" ], "AlarmDescription": "Database connectivity failure for Bookstore API (Blue).", "AlarmName": "bookstore-api-blue-db-connectivity-failed", "ComparisonOperator": "LessThanThreshold", "DatapointsToAlarm": 2, "Dimensions": [ { "Name": "Host", "Value": "bookstore-api-blue" } ], "EvaluationPeriods": 2, "MetricName": "db-connectivity", "Namespace": "Bookstore", "Period": 60, "Statistic": "Average", "Threshold": 1.0 }'aws cloudwatch put-metric-alarm --output json --cli-input-json '{ "ActionsEnabled": true, "AlarmActions": [ "arn:aws:sns:us-west-2:532151327118:PingPublicationsSNS" ], "AlarmDescription": "CDN connectivity failure for Bookstore API (Blue).", "AlarmName": "bookstore-api-blue-cdn-connectivity-failed", "ComparisonOperator": "LessThanThreshold", "DatapointsToAlarm": 2, "Dimensions": [ { "Name": "Host", "Value": "bookstore-api-blue" } ], "EvaluationPeriods": 2, "MetricName": "cdn-connectivity", "Namespace": "Bookstore", "Period": 60, "Statistic": "Average", "Threshold": 1.0 }'aws cloudwatch put-metric-alarm --output json --cli-input-json '{ "ActionsEnabled": true, "AlarmActions": [ "arn:aws:sns:us-west-2:532151327118:PingPublicationsSNS" ], "AlarmDescription": "Database connectivity failure for Bookstore API (Green).", "AlarmName": "bookstore-api-green-db-connectivity-failed", "ComparisonOperator": "LessThanThreshold", "DatapointsToAlarm": 2, "Dimensions": [ { "Name": "Host", "Value": "bookstore-api-green" } ], "EvaluationPeriods": 2, "MetricName": "db-connectivity", "Namespace": "Bookstore", "Period": 60, "Statistic": "Average", "Threshold": 1.0 }'aws cloudwatch put-metric-alarm --output json --cli-input-json '{ "ActionsEnabled": true, "AlarmActions": [ "arn:aws:sns:us-west-2:532151327118:PingPublicationsSNS" ], "AlarmDescription": "CDN connectivity failure for Bookstore API (Green).", "AlarmName": "bookstore-api-green-cdn-connectivity-failed", "ComparisonOperator": "LessThanThreshold", "DatapointsToAlarm": 2, "Dimensions": [ { "Name": "Host", "Value": "bookstore-api-green" } ], "EvaluationPeriods": 2, "MetricName": "cdn-connectivity", "Namespace": "Bookstore", "Period": 60, "Statistic": "Average", "Threshold": 1.0 }'
Here is the updated architecture diagram for the Bookstore app at the end of Resiliency Stage 3.
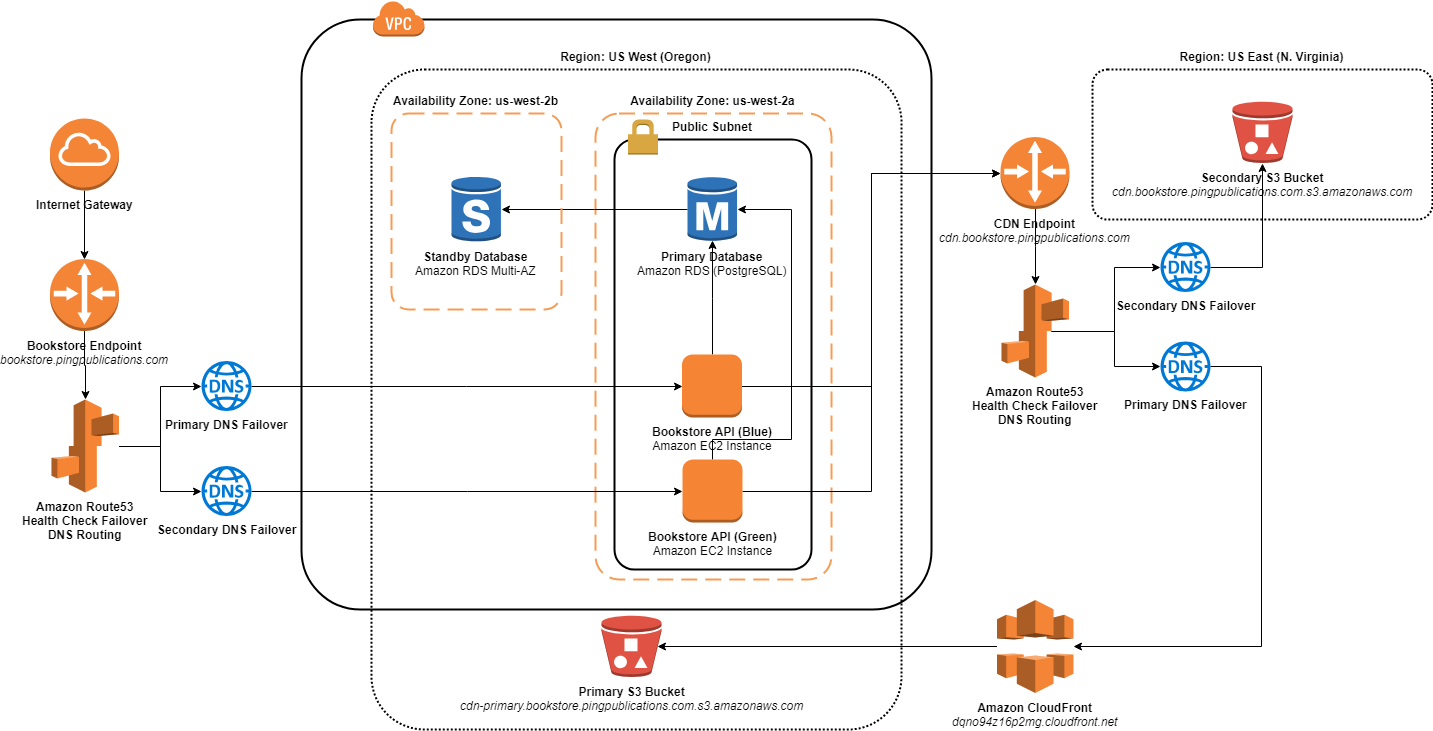 Bookstore App Architecture
Bookstore App Architecture
Performing a DB Failure Simulation Test
To meet the Stage 3 criteria of performing “frequent, semi-automated tests” we can use Chaos Engineering tools like Gremlin to easily schedule automated attacks on relevant services and machines. This allows your team to properly prepare for, evaluate, and respond to the outcome of these tests.
For the Bookstore example application, we’re simulating a failure of the database by preventing the blue environment from establishing a database connection.
-
Schedule a Gremlin
BlackholeAttack targeting thebookstore-api-blueenvironment that specifies the primary database endpoint (db.bookstore.pingpublications.com) as aHostname. Check out the Gremlin API or documentation for more details on creating Gremlin Attacks.This will automatically simulate a failure of the
bookstore-api-blueinstance’s ability to connect to the primary database endpoint, which causes the customdb-connectivitymetrics to fail and trigger the subsequent Amazon Cloudwatch alarm. -
Check the status of the
bookstore-db-connectivityservice to confirm that the health check is now failing.$ sudo systemctl status bookstore-db-connectivity.service [...] Nov 25 21:18:02 bookstore-api-blue db-connectivity.sh[785]: Connection to db.bookstore.pingpublications.com 5432 port [tcp/postgresql] succeeded! Nov 25 21:18:18 bookstore-api-blue db-connectivity.sh[785]: Connection to db.bookstore.pingpublications.com 5432 port [tcp/postgresql] failed! Nov 25 21:18:49 bookstore-api-blue db-connectivity.sh[785]: Connection to db.bookstore.pingpublications.com 5432 port [tcp/postgresql] failed! -
Use
aws cloudwatch get-metric-statisticsto check thedb-connectivitymetric around this time to see the actual metric values reported in AWS.$ aws cloudwatch get-metric-statistics --metric-name db-connectivity --start-time 2018-11-25T21:17:00Z --end-time 2018-11-25T21:24:00Z --period 60 --namespace Bookstore --statistics Average --dimensions Name=Host,Value=bookstore-api-blue --query "Datapoints[*].{Timestamp:Timestamp,Average:Average}" --output json [ { "Timestamp": "2018-11-25T21:20:00Z", "Average": 0.0 }, { "Timestamp": "2018-11-25T21:18:00Z", "Average": 0.25 }, { "Timestamp": "2018-11-25T21:19:00Z", "Average": 0.0 }, { "Timestamp": "2018-11-25T21:23:00Z", "Average": 1.0 }, { "Timestamp": "2018-11-25T21:17:00Z", "Average": 1.0 }, { "Timestamp": "2018-11-25T21:22:00Z", "Average": 0.8 }, { "Timestamp": "2018-11-25T21:21:00Z", "Average": 0.0 } ]Here we see the
db-connectivityhealth is acceptable (1.0) until it starts to drop around21:18:00, then remains at0.0for a few minutes before returning to healthy status. -
This metric failure triggered the
bookstore-api-blue-db-connectivity-failedAmazon Cloudwatch alarm that we also created. This can be confirmed by checking the alarm history status around that same time period.$ aws cloudwatch describe-alarm-history --alarm-name bookstore-api-blue-db-connectivity-failed --history-item-type StateUpdate --start-date 2018-11-25T21:17:00Z --end-date 2018-11-25T21:28:00Z --output json --query "AlarmHistoryItems[*].{Timestamp:Timestamp,Summary:HistorySummary}" [ { "Timestamp": "2018-11-25T21:24:09.620Z", "Summary": "Alarm updated from ALARM to OK" }, { "Timestamp": "2018-11-25T21:20:09.620Z", "Summary": "Alarm updated from OK to ALARM" } ]Here we see that the alarm was triggered at
21:20:09.620and remained for four minutes before returning toOKstatus.
Since an actual database failure is handled by the Multi-AZ Amazon RDS configuration created in Stage 2 - Database Failure Test, this automated critical dependency failure test doesn’t currently trigger any actual failover actions. However, alarms are now configured to easily hook into disaster recovery actions as progress is made through the final Resiliency Stages.
Performing a CDN Failure Simulation Test
We use the same steps as above to perform a scheduled, automated Gremlin Blackhole Attack to simulate failure of the CDN for our bookstore-api-blue environment. Simply changing the db- references to cdn- and the relevant endpoints will do the trick. However, for brevity’s sake, we won’t include the step-by-step instructions for doing so within this section.
Resiliency Stage 3 Completion
Your team has been performing semi-automated tests at a regular cadence, has executed at least one resiliency experiment in production, and has disseminated all test results to the entire team. With that, Resiliency Stage 3 is now complete. Revenue loss and support costs should finally be dramatically dropping as fewer failures occur, and those that do happen last for much shorter periods. In Chaos Engineering Through Staged Resiliency - Stage 4 we’ll explore automating resiliency testing in non-production, along with semi-automation of our disaster recovery failovers.